信息论与编码理论笔记
第二章 离散信源及其信息测度
2.1 信源的数学模型及分类
无记忆:随机变量之间没有相互依赖
平稳:各随机变量概率分布相同
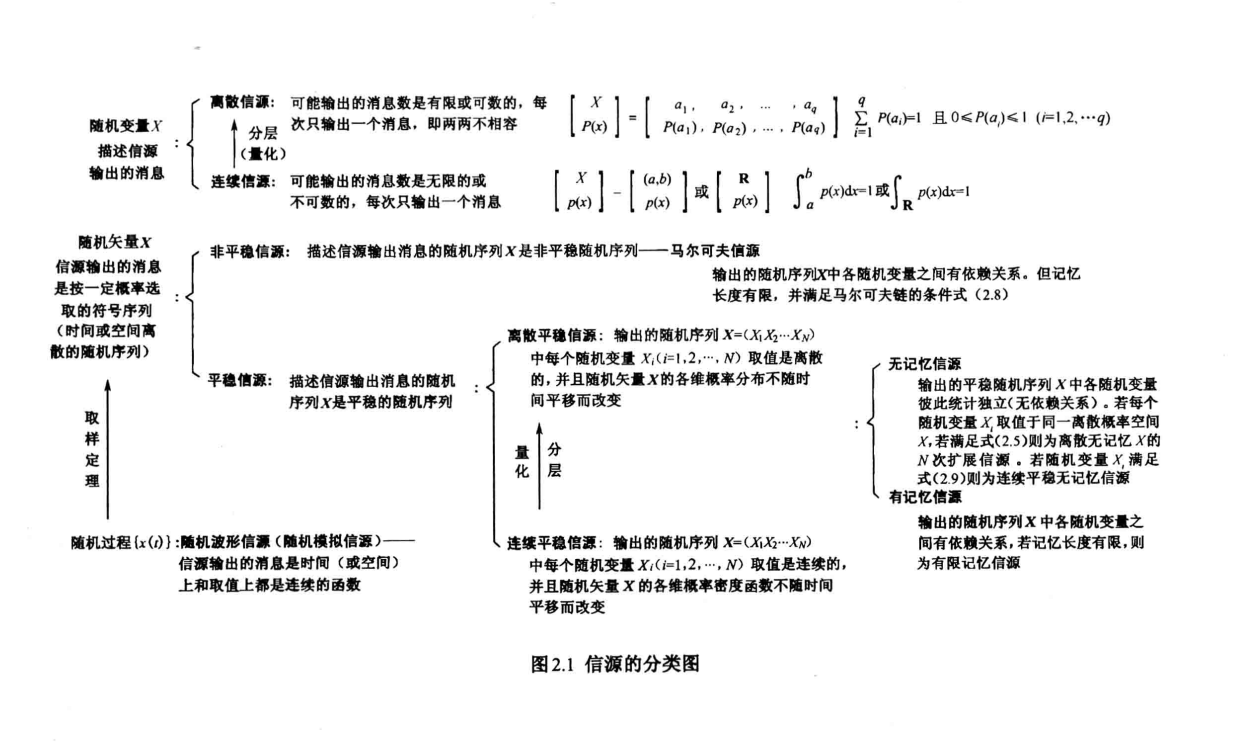
信源是信息的来源,是产生消息或消息序列的源泉。根据信源输出消息的随机性质,可以对信源进行分类。
我们并不关注信源的内部,将其视为一个黑箱,我们只关注信源的输出
2.1.1 随机变量描述信源消息
一维连续信源和一维离散信源
适用于信源可能输出的消息数是有限或可数的,且每次只输出一个消息的情况。
例如,扔一颗质地均匀的骰子,研究下落后朝上一面的点数。
特点:
- 每次实验只出现一个点数(消息)。
- 每个点数的出现是随机的。
- 点数必定为1,2,3,4,5,6中的某一个。
表示:
- 符号集 A={a1,a2,a3,a4,a5,a6} 表示基本消息集合。
- 离散型随机变量 X 描述信源输出的消息,其样本空间为 A。
- X 的概率分布即为各消息出现的先验概率,例如 P(X=ai)=61。
2.1.2 随机矢量描述信源消息
适用于信源输出的消息由一系列符号序列组成,其中每个符号的出现是不确定的、随机的。
适用场景:
- 中文自然语言作为信源:样本空间 A 为所有汉字和标点符号的集合,汉字和标点符号构成的序列即为中文句子和文章(即消息)。
- 离散化平面灰度图像信源:从 XY 平面空间上来看,每幅黑白灰度画面是一系列空间离散的灰度值符号,空间每一点的符号(灰度值)又是随机的。
特点:
- 信源输出的消息为按一定概率选取的符号序列。
- 时间或空间上离散的一系列随机变量(随机矢量)。
2.1.3 随机过程描述信源消息
适用于信源输出的消息是时间和取值都是连续的情况,例如语音信号、热噪声信号。
特点:
- 信源输出的消息是时间(或空间)上和取值上都是连续的。
- 用随机过程 {x(t)} 描述,更一般地说,实际信源输出的消息常常是时间和取值都是连续的。
2.2 离散信源的信息熵
2.2.1 自信息
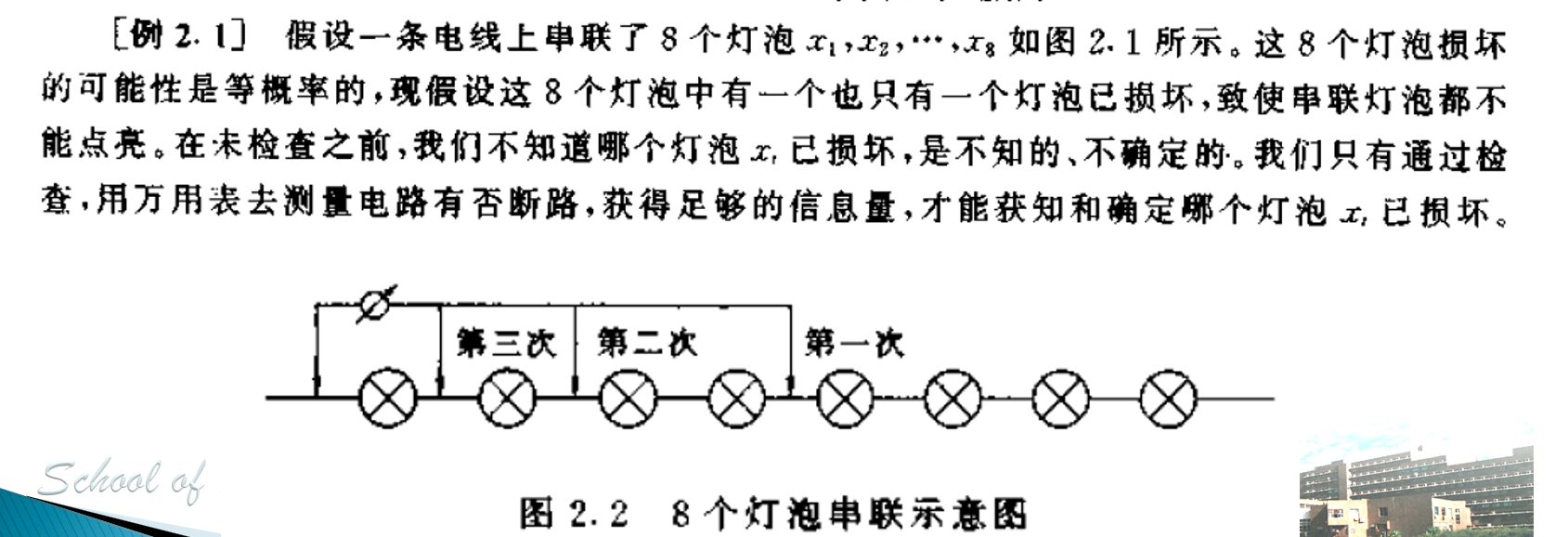
单符号离散信源中,信息量与不确定性相关。事件发生的不确定性越大,一旦它发生并被接收者收到,消除的不确定性就越大,获得的信息量也就越大。
定义:
I(xi)=logP(xi)1=−logP(xi)
单位:
- 1 奈特 = log2e 比特 ≈1.443 比特
- 1 哈特 = log210 比特 ≈3.322 比特

不确定性与发生概率
两个独立事件的联合信息量应等于它们分别的信息量之和。即统计独立信源的信息量等于它们分别的信息量之和。
2.2.1.1 自信息
- 自信息含义:
- 当事件 xi 发生以前:表示事件 xi 发生的不确定性。
- 当事件 xi 发生以后:表示事件 xi 所含有(或所提供)的信息量。在无噪信道中,事件 xi 发生后,能正确无误地传输到收信者,所以 I(xi) 可代表接收到消息 xi 后所获得的信息量。这是因为消除了 I(xi) 大小的不确定性,才获得这么大小的信息量。
- 联合自信息
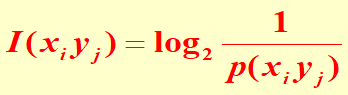
- 两个随机事件相互独立时,同时发生得到的信息量,等于各自自信息量之和。
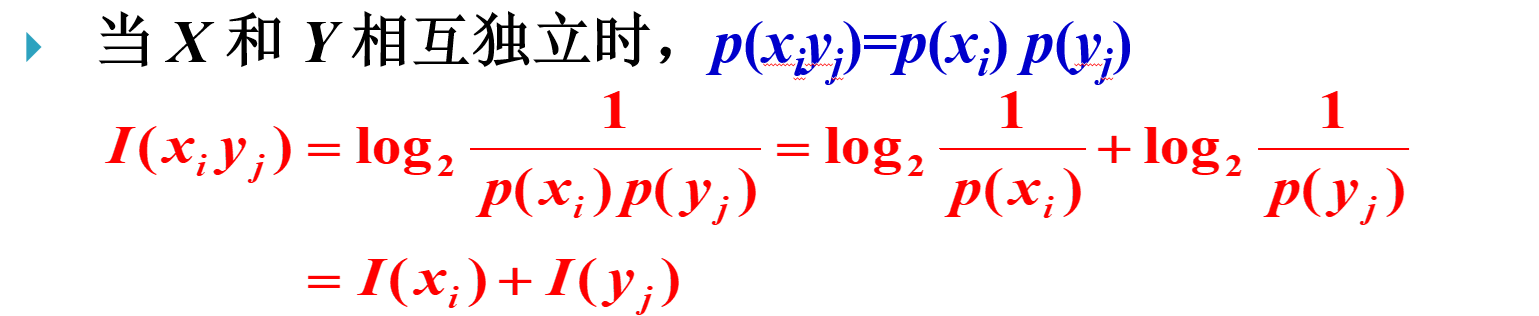
- 条件自信息
- 设 yj 条件下,发生 xi 的条件概率为 p(xi/yj),那么它的条件自信息量 I(xi/yj) 定义为:
I(xi/yj)=log2p(xi/yj)1
表示在特定条件下(yj 已定)随机事件 xi 所带来的信息量。
- 同理,xi 已知时发生 yj 的条件自信息量为:
I(yj/xi)=log2p(yj/xi)1
自信息量、条件自信息量和联合自信息量之间的关系
- 联合自信息量 I(xi,yj) 可以表示为:
- 联合自信息量可以分解为自信息量和条件自信息量之和。
I(xi,yj)=log2p(xi)p(yj/xi)1=I(xi)+I(yj/xi)
=log2p(yj)p(xi/yj)1=I(yj)+I(xi/yj)
这些公式展示了条件自信息量、自信息量和联合自信息量之间的关系。
习题 2.4(重点)
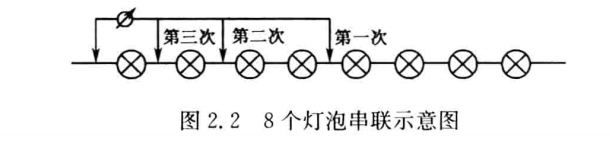
问题:设有 12 枚同值硬币,其中有一枚为假币。只知道假币的重量与真币的重量不同,但不知究竟是重还是轻。现采用比较天平左右两边轻重的方法来测量(因无砝码)。为了在天平上称出哪一枚是假币,试问至少必须称多少次?
在信息论的角度下,考虑以下事件:
- “12枚硬币中,某一枚为假币”该事件发生的概率为 P=121。
- “假币的重量比真的轻,或重”该事件发生的概率为 P=21。
为确定哪一枚是假币,需要消除上述两事件的联合不确定性。由于二者是独立的,因此有:
I=log12+log2=log24 比特
而用天平称时,有三种可能性:重、轻、相等,三者是等概率的,均为 P=31,因此天平每一次消除的不确定性为 I=log3 比特。
因此,必须称的次数为:
I2I1=log3log24≈2.9 次
因此,至少需称 3 次。
习题2.5
居住在某地区的女孩中有 25% 是大学生,在女大学生中有 75% 是身高 1.6 米以上的,而女孩中身高 1.6 米以上的占总数一半。假如我们得知“身高 1.6 米以上的某女孩是大学生”的消息,问获得多少信息量?
解答:
设:
- A 表示“是大学生”
- B 表示“身高 1.6 米以上”
已知:
- P(A)=0.25
- P(B∣A)=0.75
- P(B)=0.5
要求的信息量是 I(B→A),即已知 B 发生后,关于 A 的不确定性减少量。
根据贝叶斯公式:
P(A∣B)=P(B)P(B∣A)P(A)=0.50.75×0.25=0.375
信息量:
I(B→A)=logP(A∣B)1=log0.3751≈1.415 比特
2.2.2 信息熵
信息量是一个随机变量
信息熵是信源的平均信息量,是自信息的数学期望。
定义:
H(X)=E[I(X)]=−i=1∑np(xi)logp(xi)
单位:比特/符号(以 2 为底)
意义:
- 表示信源输出后每个消息(符号)所提供的平均信息量。
- 表示信源输出前,信源的平均不确定性。
- 表征信源的随机性。

信息熵与平均获得的信息量
信息熵是信源的平均不确定性的描述。在一般情况下它并不等于平均获得的信息量。
- 只有在无噪情况下,接收者才能正确无误地接收到信源所发出的消息,消除 H(X) 大小的平均不确定性,所以获得的平均信息量就等于 H(X)。
- 在一般情况下获得的信息量是两熵之差,并不是信源熵本身。
联合熵
联合熵 H(XY) 表示输入随机变量 X,经信道传输到达信宿,输出随机变量 Y。即收、发双方通信后,整个系统仍然存在的不确定度。
H(XY)=xi∈X∑yj∈Y∑p(xiyj)logp(xiyj)1
条件熵
条件熵定义:条件熵是在联合符号集合 XY 上的条件自信息的数学期望。
H(X/Y)=j=1∑mi=1∑np(xiyj)I(xi/yj)=j=1∑mi=1∑np(xiyj)log2p(xi/yj)1
H(Y/X)=E[I(yj/xi)]=i=1∑nj=1∑mp(xiyj)log2p(yj/xi)1
条件熵是一个确定的值。
2.3 信息熵的基本性质和定理
2.3.1 非负性
H(X)≥0
因为 0≤p(xi)≤1,所以 logp(xi)≤0,从而 −p(xi)logp(xi)≥0,所以熵 H(X)≥0。
2.3.2 对称性
黑箱
当变量 p(x1),p(x2),…,p(xn) 的顺序任意互换时,熵函数的值不变。
2.3.3 扩展性
含义:信源的取值增多时,若这些取值对应的概率很小(接近于零),则信源的熵不变。
p→0limH(p,1−p)=H(1−p)
2.3.4 确定性
H(1,0)=H(1,0,0)=…=0
当某分量 p(xi)=1 时,熵 H(X)=0。
2.3.5 可加性(联合熵 = 信息熵 + 条件熵)
H(XY)=H(X)+H(Y∣X)
2.3.6 上凸性
H[αP1+(1−α)P2]>αH(P1)+(1−α)H(P2)
2.3.7 极值性
离散无记忆信源输出 n 个不同的信息符号,当且仅当各个符号出现概率相等时(即 p(xi)=n1),熵最大。
2.3.8 最大离散熵定理
定理:离散无记忆信源输出 n 个不同的信息符号,当且仅当各个符号出现概率相等时(即 p(xi)=n1),熵最大。
2.4 扩展信源
扩展信源
举例:电报系统,发出的是一串有(表示为0)无脉冲(表示为1)的信号系列,表示为010…01.
实际的信源输出的消息是时间或空间上离散的一系列随机变量。这类信源每次输出的不是一个单个的符号,而是一个符号序列。在信源输出的序列中,每一位出现哪个符号都是随机的,而且一般前后符号的出现是有统计依赖关系的。这种信源称为扩展信源/多符号离散信源
2.4.1 离散无记忆信源的扩展
- 把信源输出的序列看成是一组一组发出的。
- 例1:电报系统中,认为每二个二进制数字组成一组。信源输出由 2 个二进制数字组成的一组组符号。这时可以将它们等效看成一个新的信源,由 4 个符号 00,01,10,11 组成,该信源称为二进制无记忆信源的二次扩展。
- 例2:把每 3 个二进制数字组成一组,这样长度为 3 的二进制序列就有 8 种不同的序列,等效成一个具有 8 个符号的信源,称为二进制无记忆信源的三次扩展信源。
二进制无记忆信源的 N 次扩展:把每 N 个二进制数字组成一组,则信源等效成一个具有 2N 个符号的新信源,称为二进制无记忆信源的 N 次扩展信源。
2.4.1 离散无记忆信源的熵
离散无记忆信源的 N 次扩展信源的熵等于离散信源熵的 N 倍,即:
H(XN)=NH(X)
2.4.2 离散平稳信源
离散平稳信源的输出随机序列的统计特性与时间的推移无关。
联合熵:
H(X1X2…XN)
- 二维离散平稳信源的联合熵 H(X1X2) 与单符号熵 H(X) 的关系是:
- 答案:B. H(X1X2)≤2H(X)
- 解析:对于二维离散平稳信源,符号之间可能存在依赖关系,因此联合熵 H(X1X2) 通常小于或等于两倍的单符号熵 2H(X)。只有当两个符号完全独立时,联合熵才等于两倍单符号熵。
条件熵:
H(XN∣X1X2…XN−1)
极限熵:

H∞=N→∞limHN(X)=N→∞limH(XN∣X1X2…XN−1)
2.5 马尔可夫信源
2.5.1 马尔可夫信源的定义
马尔可夫信源的输出符号和所处的状态满足以下条件:
- 某一时刻信源符号的输出只与此刻信源所处的状态有关,与以前的状态和以前的输出符号都无关。
- 信源处于某一状态时,再发出一个符号后所处的状态将发生改变。
2.5.2 m 阶马尔可夫信源
m 阶马尔可夫信源的数学模型可由一组信源符号集和一组条件概率确定。当前发出的符号只与前 m 个符号有关,与更前面的符号无关。
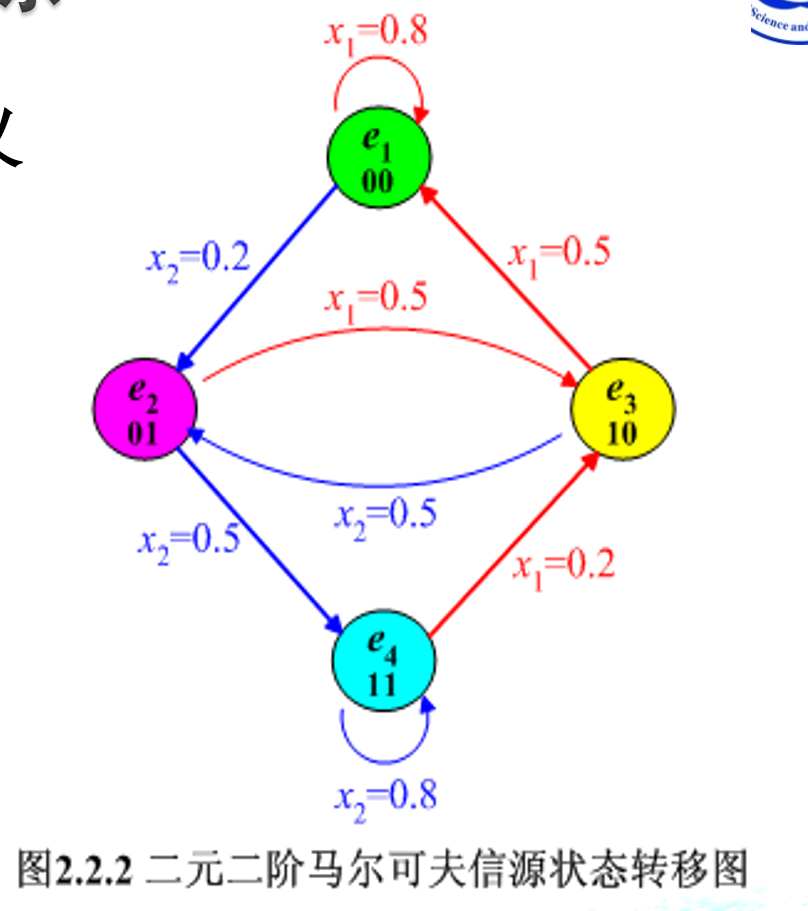
马尔可夫信源的输出符号和所处的状态满足以下两个条件:
- 无记忆性:
某一时刻信源符号的输出只与此刻信源所处的状态有关,与以前的状态和以前的输出符号都无关。数学表达式为:
P(Xl=xk∣Sl=ei,Xl−1=xk1,Sl−1=ej,…)=P(xk∣ei)
当具有时齐性时有:
P(xk∣ei)=p(xk∣ei)
- 状态转移:
信源在 l 时刻所处的状态由当前的输出符号和前一时刻 (l−1) 信源的状态唯一确定。数学表达式为:
P(Sl=ej∣Xl=xm,Sl−1=ei)={01if xm=f(ei,ej)if xm=f(ei,ej)
其中 f(ei,ej) 是状态转移函数,表示从状态 ei 转移到状态 ej 时输出的符号。
这些条件定义了马尔可夫信源的基本特性,即当前状态只依赖于前一个状态,这种特性使得马尔可夫模型在许多领域中非常有用,尤其是在时间序列分析和自然语言处理中。
2.6 信源剩余度与自然语言的熵
2.6.1 信源剩余度
信源剩余度反映了信源输出符号序列中符号之间的依赖程度,计算公式为:
ξ=1−H0H∞
其中,H∞ 是信源的实际熵,H0=log∣A∣ 是最大熵。
2.6.2 自然语言的熵
自然语言如英语、汉语等具有较高的剩余度,意味着符号之间存在较强的依赖关系,信息熵较低。
总结
本章详细介绍了信源的分类、数学模型,以及信息熵的定义、性质和计算方法。通过习题加深了对信息熵和自信息的理解,掌握了如何计算信息量和确定称量次数等实际问题。
)
