讲座内容概述
本次讲座是 MIT 6.S191 课程的第二讲,主题为深度序列建模,重点介绍循环神经网络(RNN)、Transformer 和注意力机制等概念。讲座由 Ava 指导,旨在为学生打下序列建模的基础,以便更好地理解后续关于大型语言模型等前沿主题的讲座。
RNN和transformer都是为了解决长文本的探索架构
序列建模的概念与应用
序列建模是一种处理序列数据的方法,广泛应用于多个领域:
- 语音处理:将语音信号分解为一系列声波进行处理。
- 自然语言处理:将文本分割为字符或单词序列进行处理。
- 医疗信号处理:如心电图(ECG)等。
- 金融市场分析:股票价格预测等。
- 生物序列分析:核苷酸或蛋白质序列。
- 气象与视频处理:天气数据和运动视频等。
现实生活中的例子
在自然语言处理领域,序列建模被广泛应用于机器翻译、情感分析、文本生成等任务。例如,谷歌翻译利用序列到序列模型将一种语言的文本序列转换为另一种语言的文本序列;在金融领域,通过对股票价格的时间序列建模,可以预测未来的股价走势,辅助投资决策。
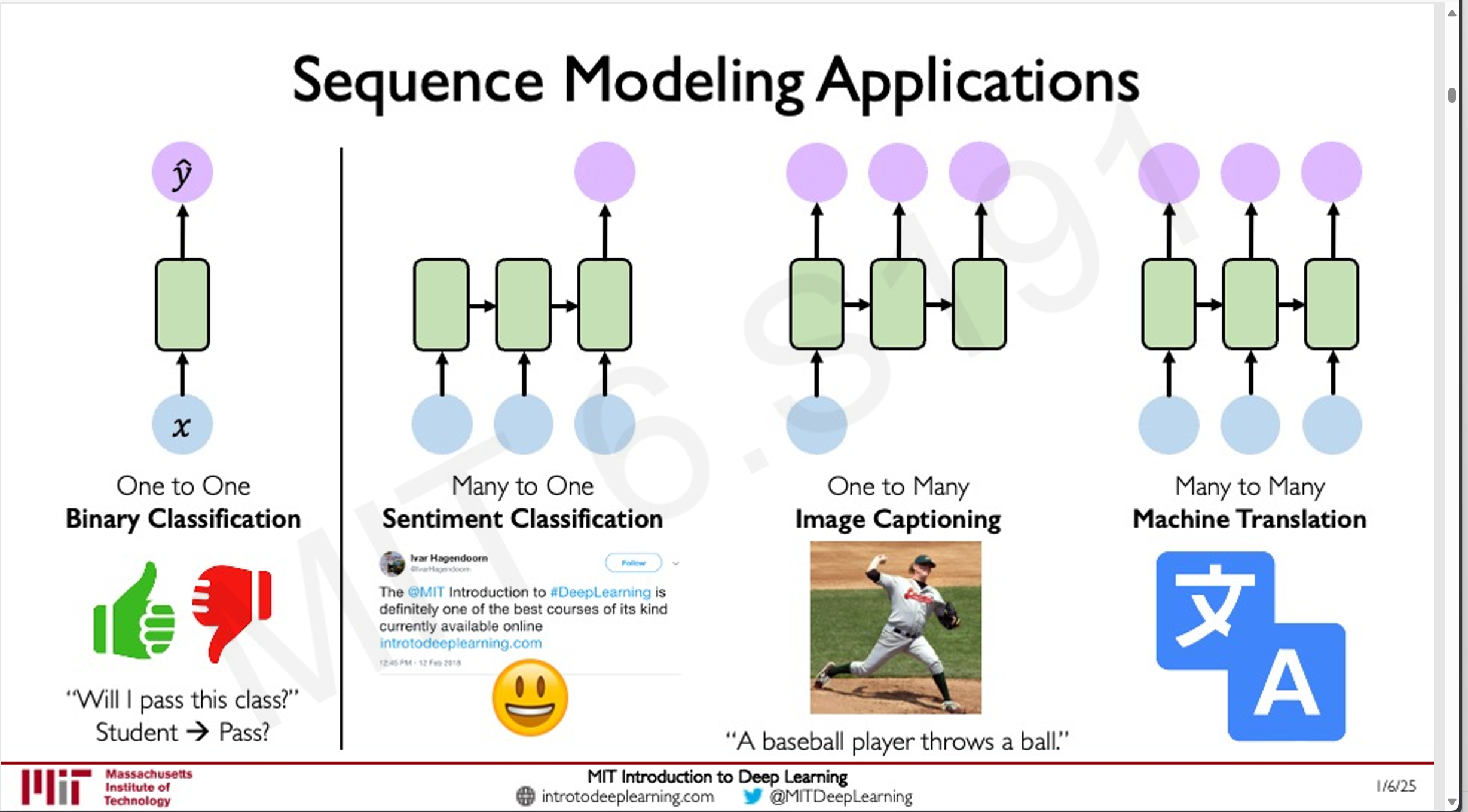
序列建模的问题形式
序列建模可以应用于多种问题形式:
- 单输入到单输出:如分类问题,判断一个句子的情感倾向(正面或负面)。
- 单输入到序列输出:如图像字幕生成,根据图像生成描述性文本。
- 序列输入到序列输出:如机器翻译,将一种语言的句子序列翻译为另一种语言的句子序列。
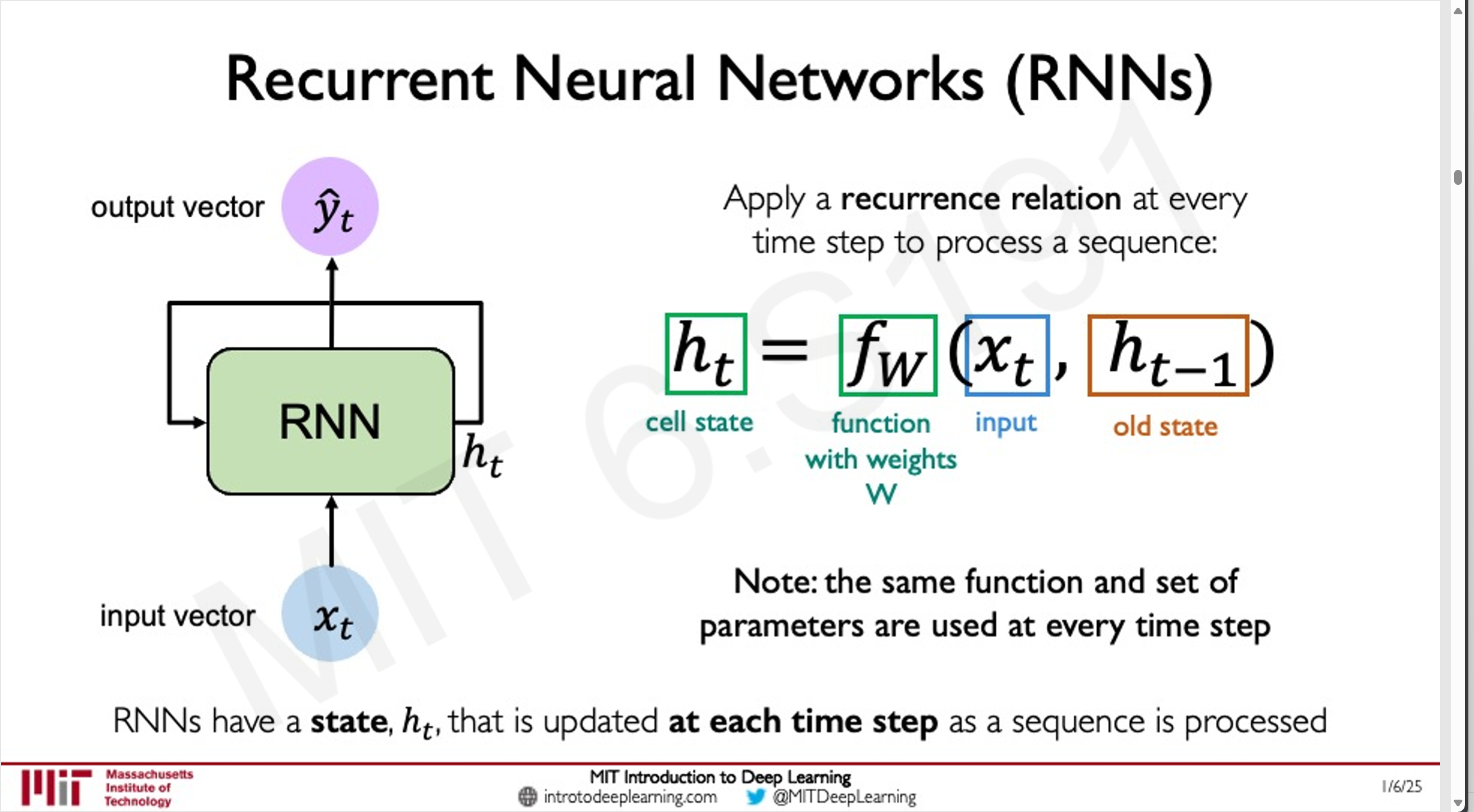
循环神经网络([[RNN]])
基本概念
RNN 是一种能够处理序列数据的神经网络架构,通过在神经元之间引入循环结构,使得网络能够保留关于过去输入的信息,从而对序列中的时间依赖关系进行建模。
既有当前观测到的数据,也保留了历史数据,通过这些数据来预测未来。

工作原理
RNN 的核心是隐藏状态(Hidden State),它在每个时间步上不仅依赖于当前输入,还依赖于前一个时间步的隐藏状态。数学上,隐藏状态的更新可以表示为:
可以将RNN(循环神经网络)理解为一个按顺序处理信息的“窗口”。假设我们有一段文本:“我是mika”,RNN会将这段文本逐个字符或逐个词语依次输入网络。例如,它会先处理“我”,然后是“是”,接着是“mika”……通过这种方式,RNN会在每个时间步上更新其内部状态,从而记住之前的信息。
当后续再次提到“我”时,RNN可以根据之前的状态“回忆”起“我”与“mika”之间的关联。然而,RNN在处理长序列数据时有一个显著的局限性:当序列过长或数据量过大时,很容易出现梯度消失或梯度爆炸的问题。梯度消失会导致网络难以学习到长距离依赖关系,而梯度爆炸则会使训练过程不稳定。这些问题限制了RNN在处理复杂任务时的性能。
其中, 是当前时间步的隐藏状态, 是当前时间步的输入, 和 是权重矩阵, 是偏置项, 是激活函数。
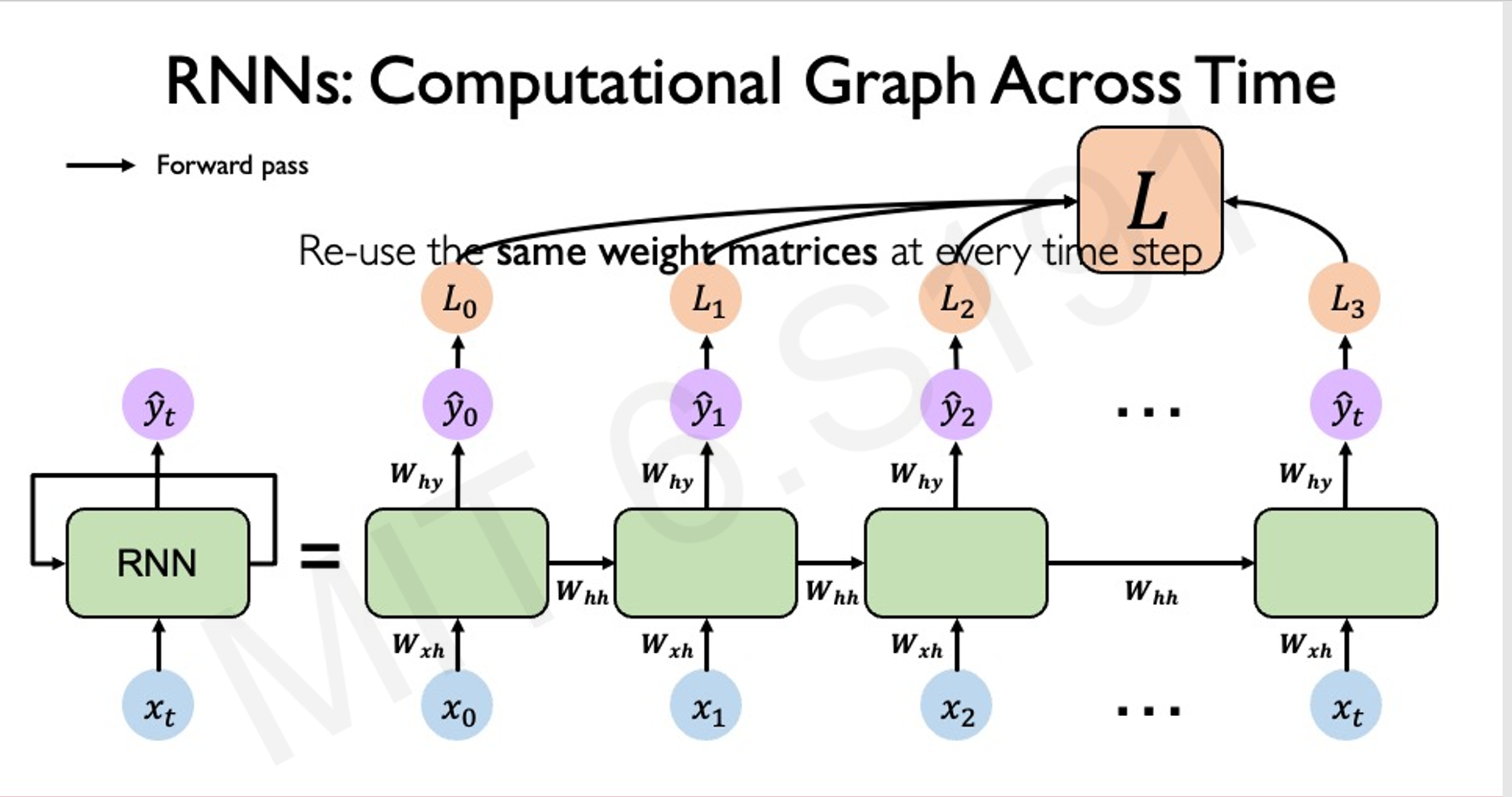
训练方法
RNN 的训练使用反向传播通过时间(Backpropagation Through Time, BPTT)算法,即将网络在时间上的展开视为一个深层网络,然后应用标准的反向传播算法进行训练。然而,RNN 在训练过程中面临梯度消失和梯度爆炸的问题,这限制了其对长序列的建模能力。
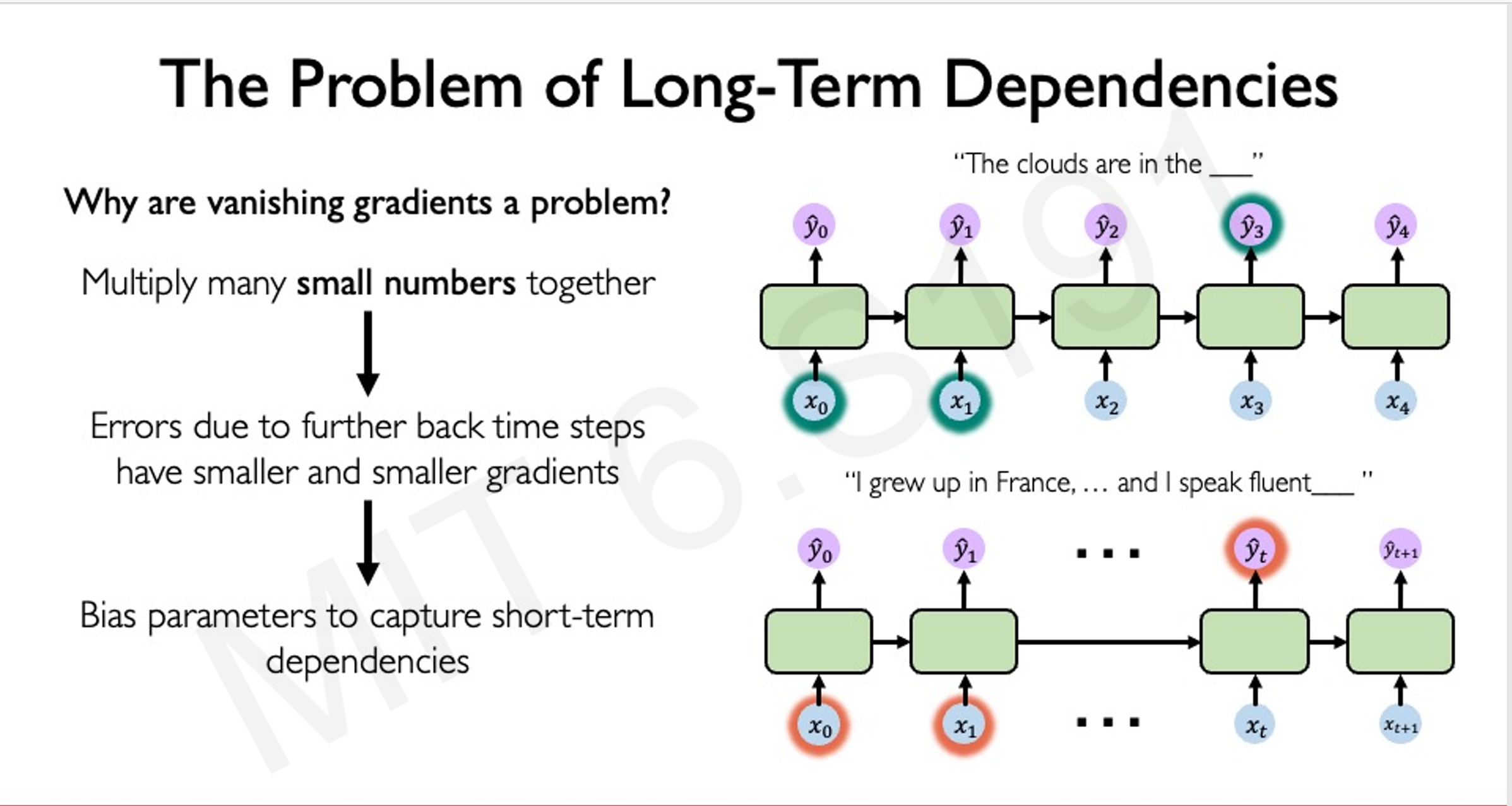
应用示例
- 音乐生成:通过训练 RNN 模型,可以根据过去的音符序列预测下一个音符,从而生成新的音乐。例如,有公司曾使用神经网络完成舒伯特未完成的交响曲。
- 文本生成:RNN 可以根据给定的文本序列生成下一个单词,实现自动写作等功能。
长短期记忆网络([[LSTM]])
LSTM 是 RNN 的一种变体,通过引入门控机制(输入门、遗忘门和输出门)来控制信息的流动,能够更好地处理长序列中的长期依赖问题。
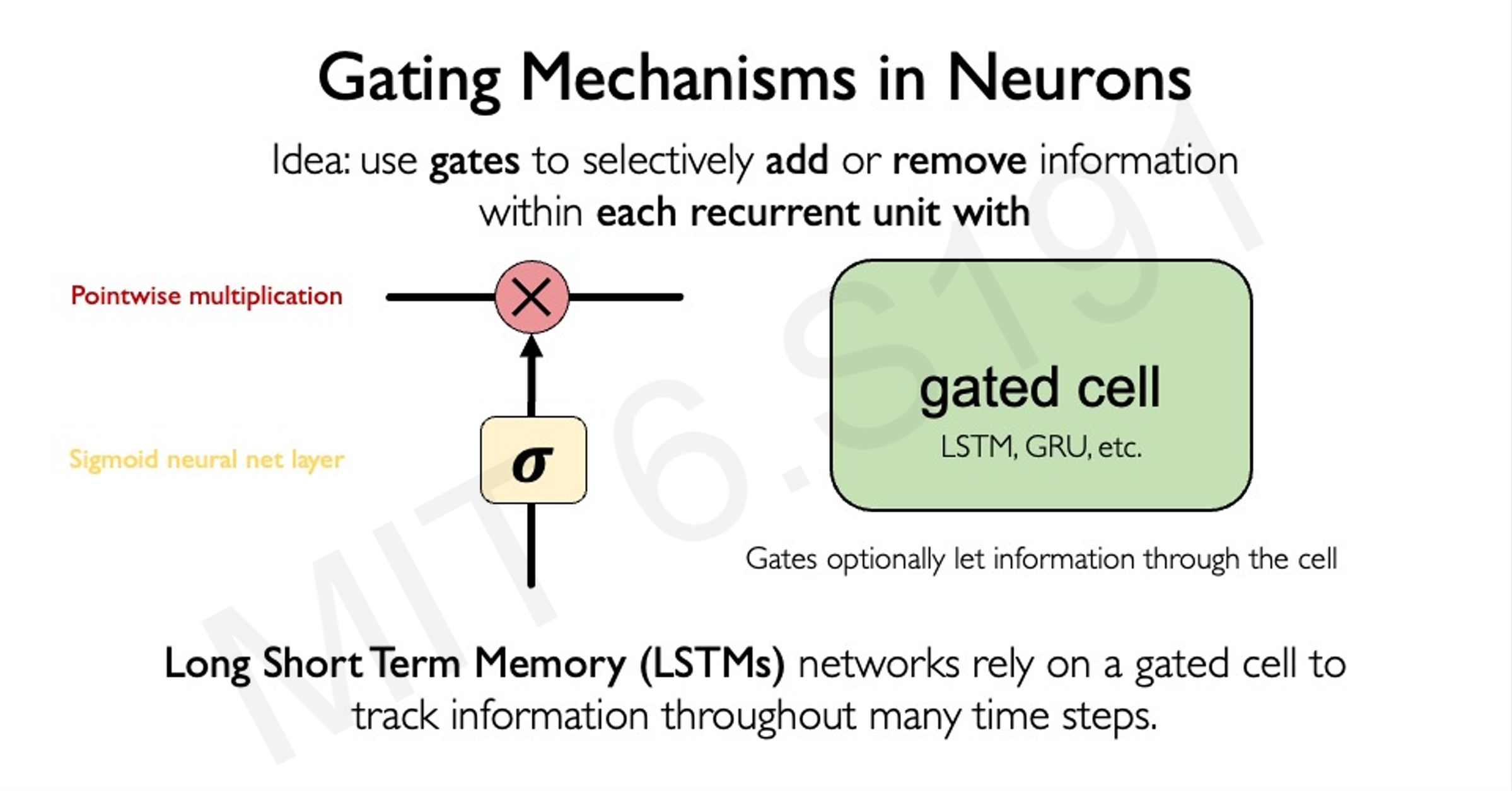
工作原理
LSTM 的隐藏状态更新涉及细胞状态(Cell State)的维护,细胞状态通过遗忘门、输入门和输出门进行调节:
其中,、 和 分别是遗忘门、输入门和输出门的输出, 是候选细胞状态, 是当前细胞状态, 表示按元素相乘。
应用示例
- 天气预报:利用 LSTM 对气象数据的时间序列进行建模,预测未来的天气情况。
- 金融市场分析:通过对股票价格序列的建模,预测股价走势,辅助投资决策。
Transformer 和注意力机制
注意力机制的基本概念
注意力机制允许模型在处理序列数据时,根据当前任务的需要,自动地关注输入序列中的不同部分。这种机制在处理长序列和需要捕捉序列中元素之间复杂关系的任务中表现出色。
自注意力机制
自注意力机制通过计算查询(Query)、键(Key)和值(Value)三个向量之间的相似度,确定序列中不同元素之间的相关性。具体来说,对于序列中的每个元素,计算其与其他元素的注意力权重,然后根据这些权重对值向量进行加权求和,得到该元素的输出表示。
其中,、 和 是通过线性变换得到的查询、键和值矩阵, 是键的维度。
假设我们有一段文本:“我是mika……”
Transformer 会将这段文本中的每个词(或标记)分别转换为一个词嵌入向量。然后,它通过自注意力机制计算每个词与序列中其他词的关联程度。
例如,当我们问到“‘我’是谁?”时,Transformer 并不会简单地将“我”与其他词进行点积运算,而是通过计算每个词的上下文权重,综合整个序列的信息来理解“我”的含义。最终,它会根据上下文关系生成一个合理的答案,比如“mika”。
这种机制使得 Transformer 能够在处理文本时充分考虑全局信息,而不仅仅是局部的词与词之间的关系。
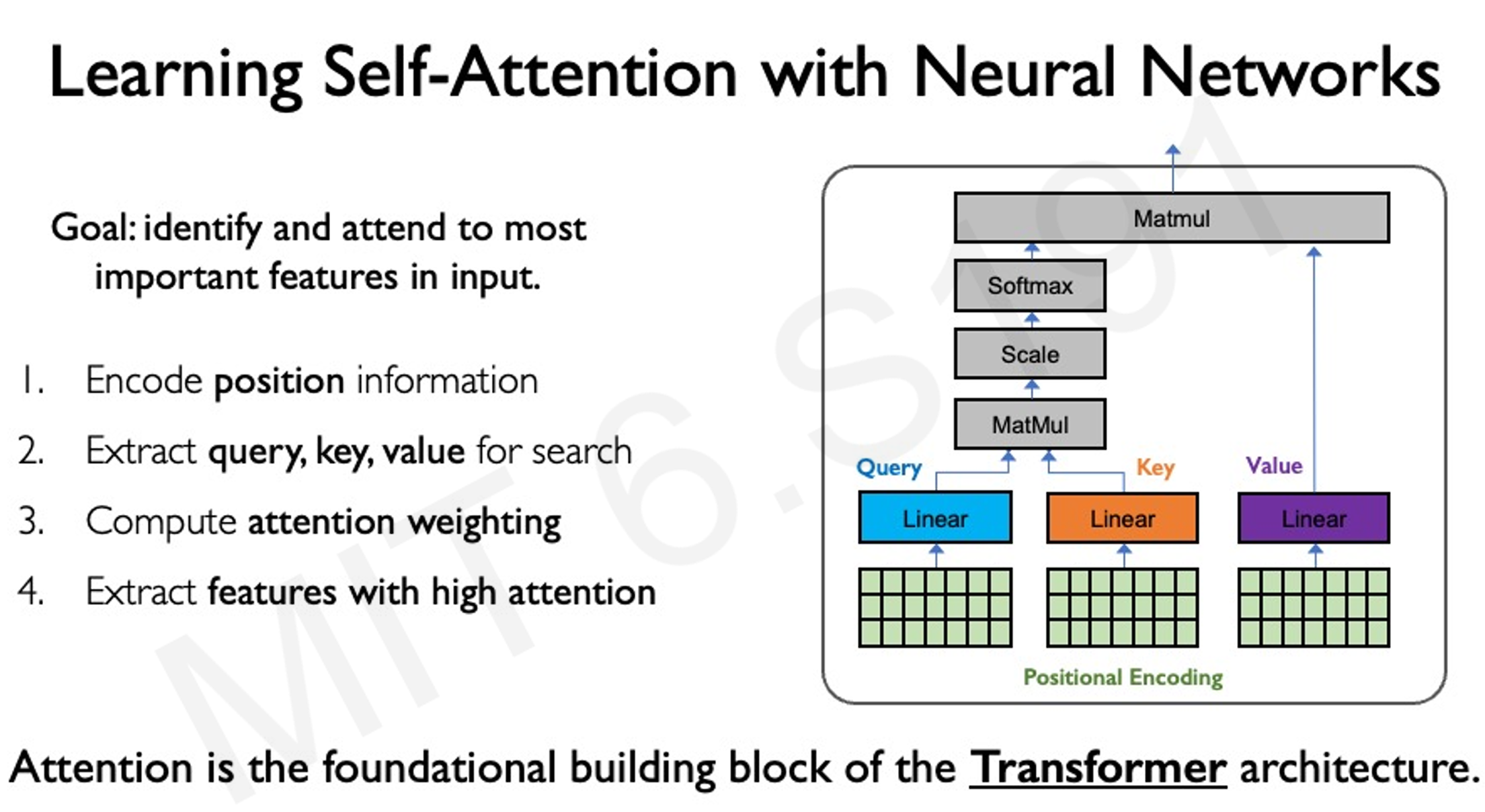
Transformer 架构
Transformer 架构基于自注意力机制,通过多头注意力(Multi-Head Attention)和前馈神经网络(Feed Forward Neural Network)的堆叠,构建强大的序列建模能力。多头注意力允许模型在不同的子空间中并行地执行注意力计算,从而捕捉更丰富的序列信息。
应用示例
- 自然语言处理:Transformer 在机器翻译、文本生成等任务中取得了显著成果,如 GPT 系列模型。
- 计算机视觉:Vision Transformer 将注意力机制应用于图像处理,通过将图像分割为 patches 并对 patches 之间的关系进行建模,实现图像分类等任务。
总结
本次讲座详细介绍了循环神经网络、长短期记忆网络、Transformer 和注意力机制等序列建模的核心概念和方法,并通过多个实际应用示例展示了这些技术在现实世界中的广泛应用。通过理解这些基础概念,学生可以为进一步学习大型语言模型等前沿主题打下坚实的基础。