第一部分:深度学习与计算机视觉简介
1.1 课程简介
- 课程主题:MIT 6.S191《深度学习入门》课程的第二天,专注于计算机视觉。
- 课程目标:探讨如何让计算机拥有视觉能力,理解并感知物理世界。
1.2 视觉能力的重要性
- 背景:视觉是人类最重要的感知能力之一,帮助我们识别情感、导航世界和操纵物体。
- 计算机视觉:让计算机通过视觉输入理解周围环境,不仅仅是静态的“看到”,还包括动态的“感知”。

1.3 深度学习在计算机视觉中的应用
- 应用场景:从机器人技术到移动计算,从医学健康到自动驾驶。
- 重要性:深度学习正在彻底改变计算机视觉算法及其应用,使其更加智能化和自动化。
第二部分:计算机视觉的基础
2.1 图像的表示
- 图像的本质:图像在计算机中被表示为一个像素值数组(矩阵)。
- 黑白图像:二维数组。
- 彩色图像:三维数组(由RGB通道组成)。
- 像素值范围:通常是 [0, 255]。
本质上是一个灰度图

2.2 计算机视觉任务的分类
- [[回归任务]]:输出连续值。output variable takes continuous value
- [[分类任务]]:输出类别标签。output variable takes class label. Can produce probability of belonging to a particular class
2.3 特征检测的重要性
我们如何区分不同的物体,通过的就是高维度的特征,比如说门窗就是房子的特征

- 手动特征提取:由人类定义特征(如眼睛、鼻子等),然后检测这些特征。
- 问题:特征提取需要专业知识,并且难以处理复杂的图像变化(如视角变化、尺度变化、遮挡等)。
第三部分:深度学习与卷积神经网络(CNN)
3.1 深度学习的优势
- 自动特征学习:深度学习模型可以从数据中自动学习特征,避免手动定义特征。
- 层次化特征表示:模型可以通过多层网络学习低级特征(边缘、斑点)到高级特征(面部结构)。
- 通过定义一个滑动窗口,对窗口里面的东西进行特征识别
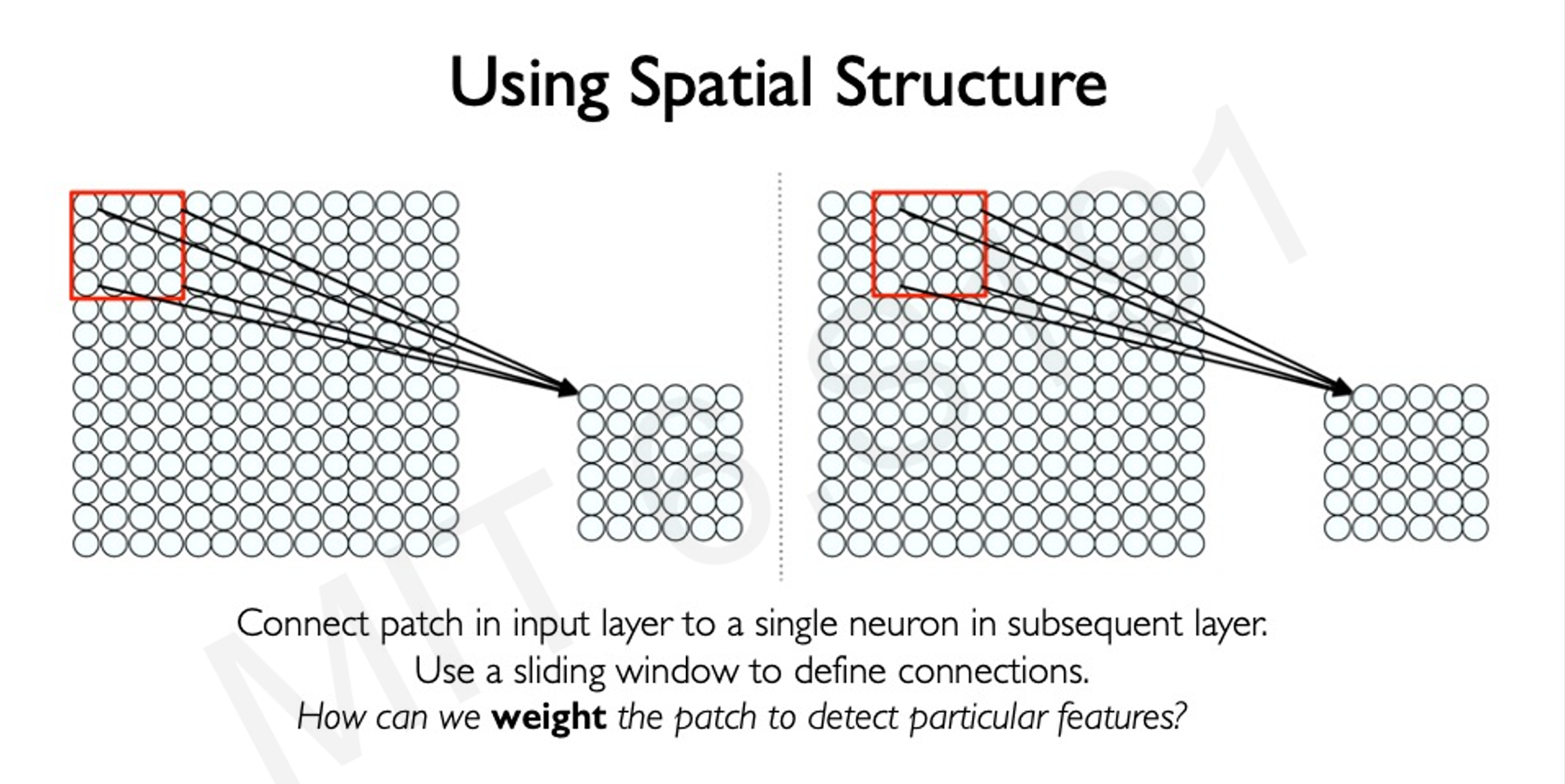
- 通过定义一个滑动窗口,对窗口里面的东西进行特征识别
3.2 卷积操作
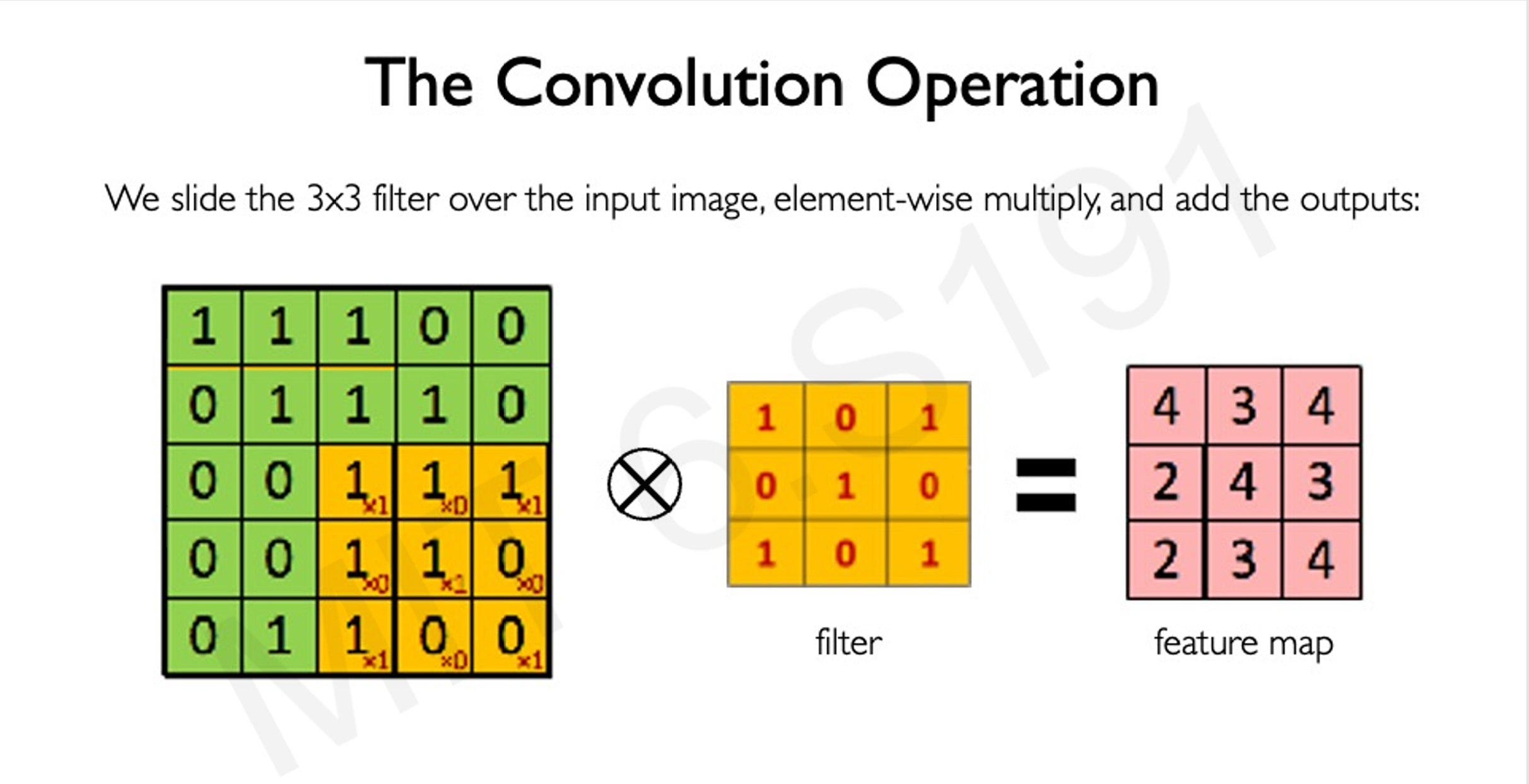
- 卷积定义:通过滤波器(filter)在图像上滑动,进行逐元素乘法和求和操作。
- 卷积的作用:提取局部特征,同时保留图像的空间结构。
- 通过将大图像转化为更多的小图像,然后在小图像中搜集信息,保留图像的空间特征
- 卷积的例子:
1
2
3
4
5
6
7
8
9
10
11
12输入图像:
1 1 0
0 1 1
0 1 1
滤波器:
1 0
0 1
卷积结果(特征图):
2 2
1 2
filter的选择
- 不同的filter有不同的效果,对于图像的卷积操作有不同的结果
- 可以通过不同的filter检测图像中的不同特征,包括直线,圆,三角形等内容
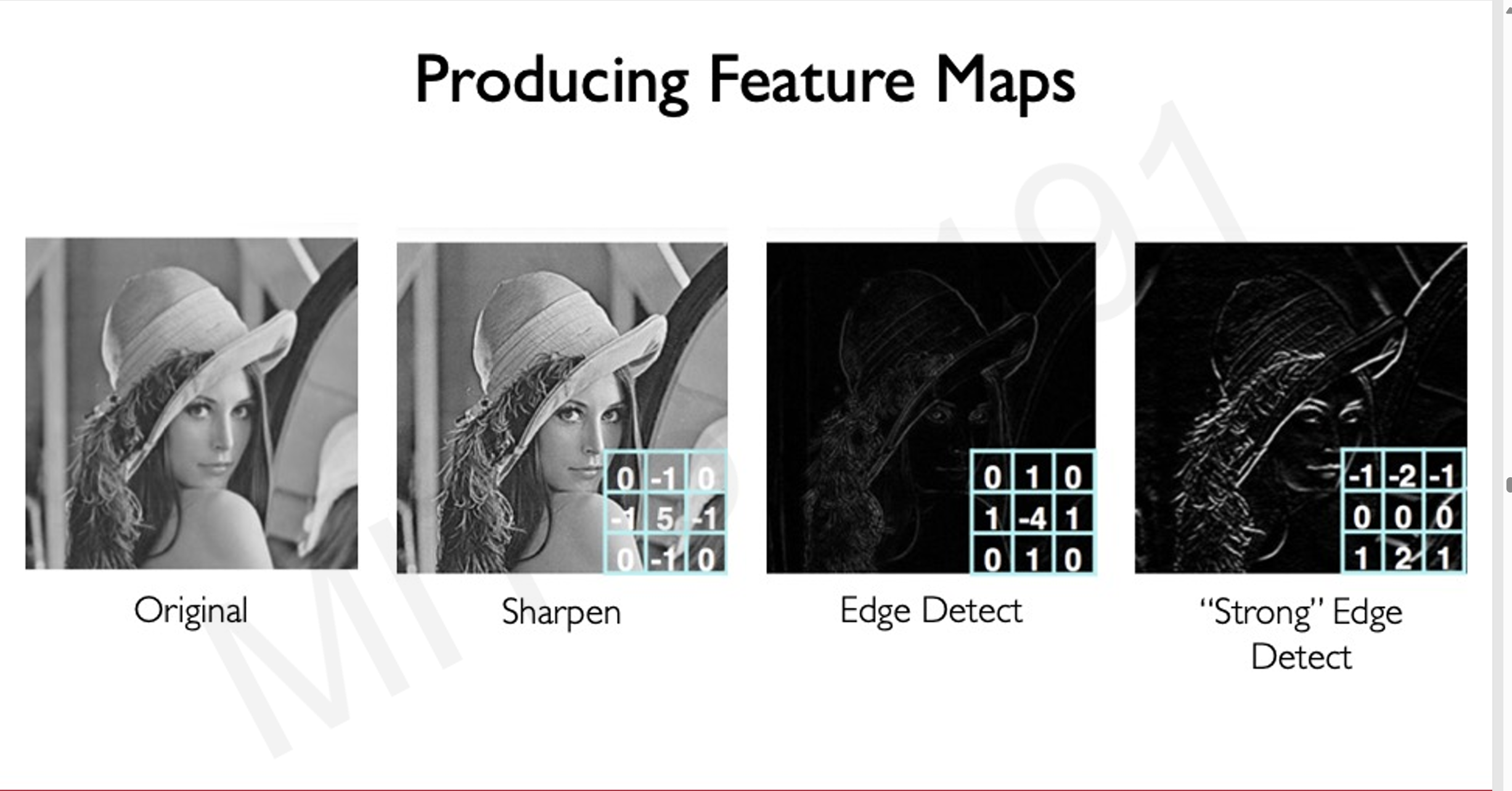
- 可以通过不同的filter检测图像中的不同特征,包括直线,圆,三角形等内容
3.3 CNN的构成
CNN是为图像分类而设计的卷积神经网络
-
主要操作:卷积、非线性激活(ReLU)、池化(下采样)。
-
[[卷积层]]:通过多个滤波器提取不同特征。
-
ReLU激活函数:将所有负值置为零,增加非线性。从而强化我们所关注的要点
-
[[池化操作]]:减少特征图的维度,保留重要特征。
-
最大池化操作,通过从每个池子内找出最大值
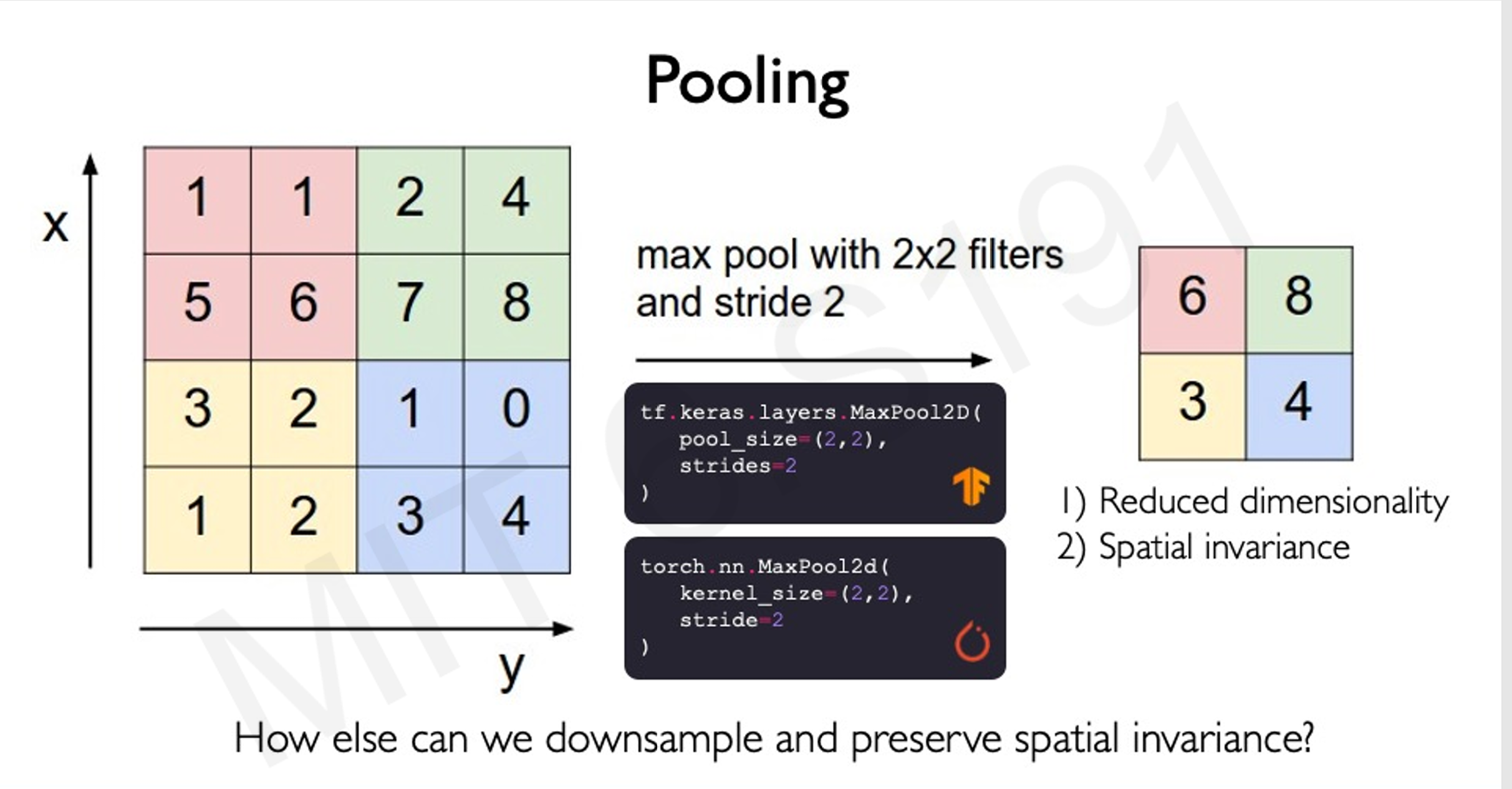
-
其实也就是控制patchs的大小而已
- 如果卷积的区域太大了,需要的计算量也会变大
- 如果卷积的区域太小了,就太过细化了,计算次数变多。
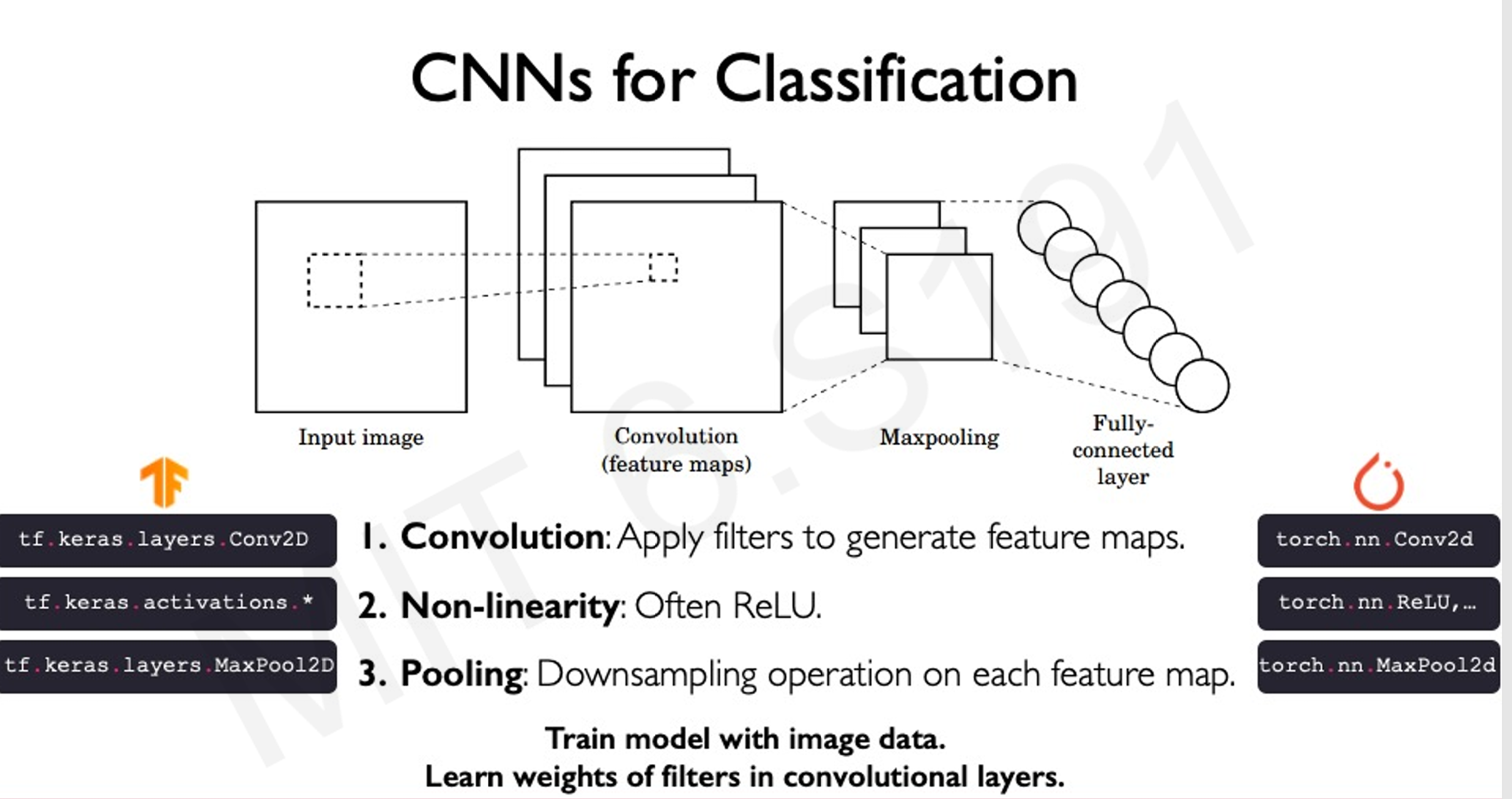
-
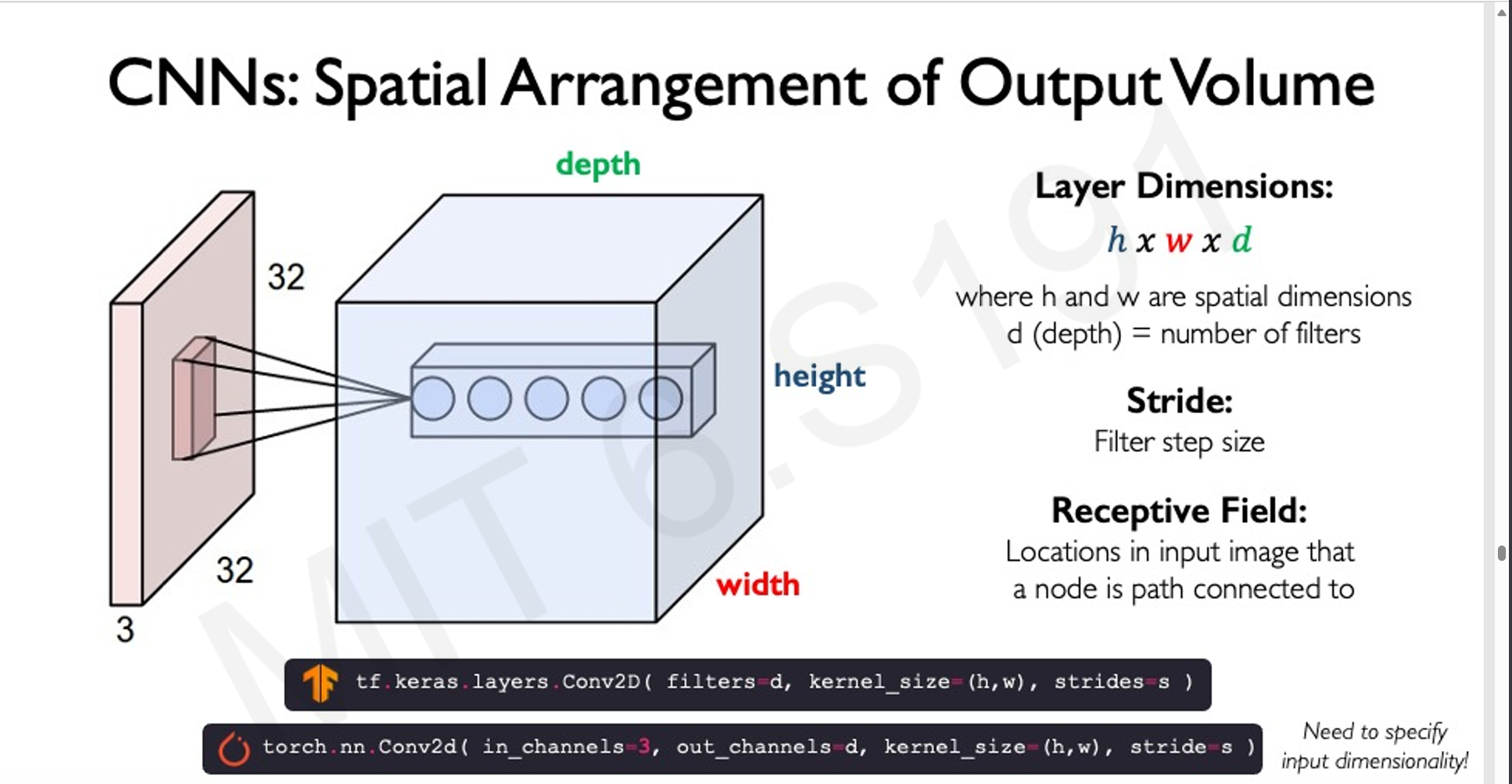

3.4 CNN架构
- 输入层:原始图像。
- 隐藏层:卷积层 + 池化层 + ReLU激活。
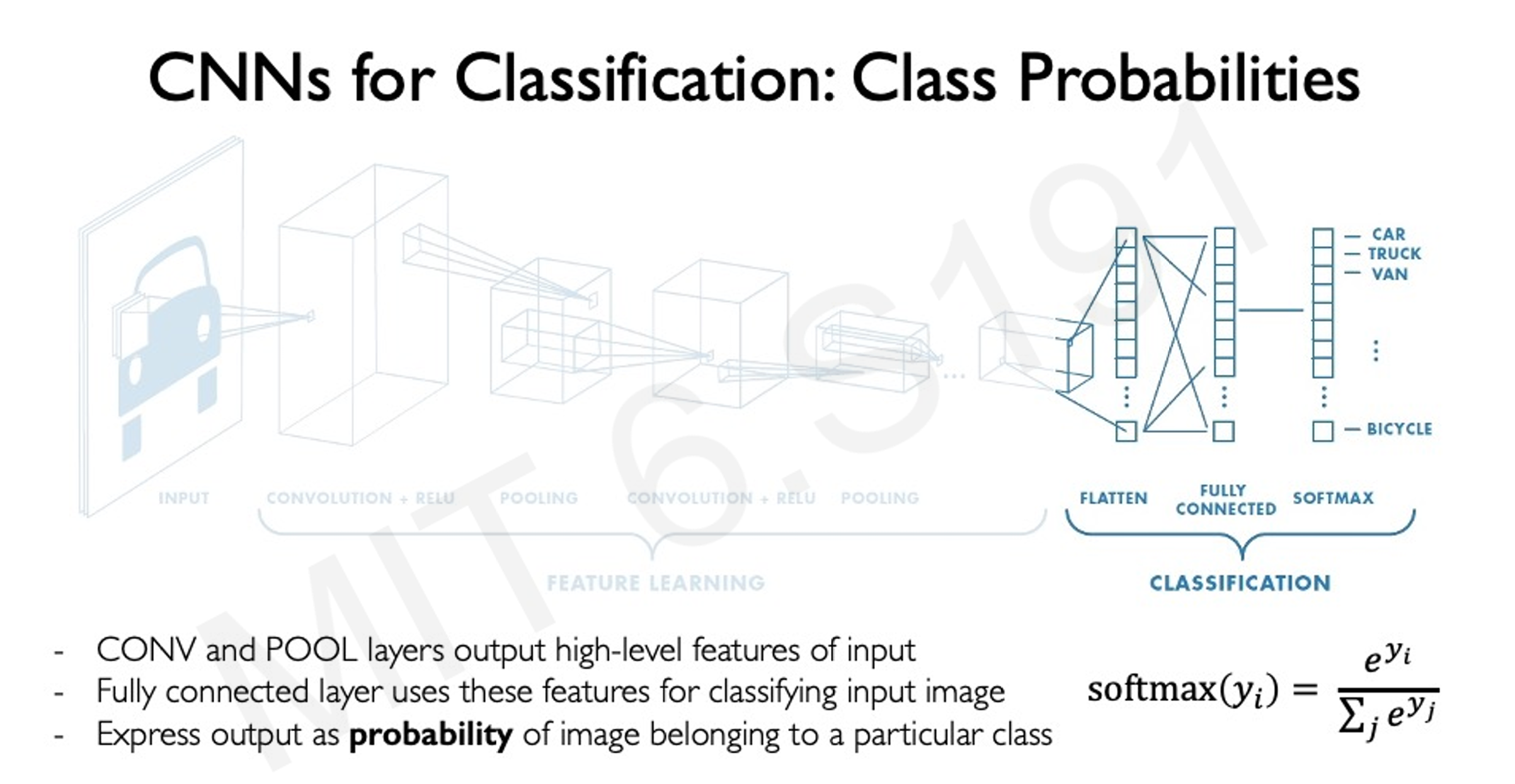
- 输出层:全连接层 + Softmax分类器,输出类别概率分布。
- Softmax是一个获取结果的函数,注意,所有的结果之和是1。
- 既然是分类,对于该物体的结果也就是一个概率分布,比如可能有0.3的概率是猫,0.7的概率是狗
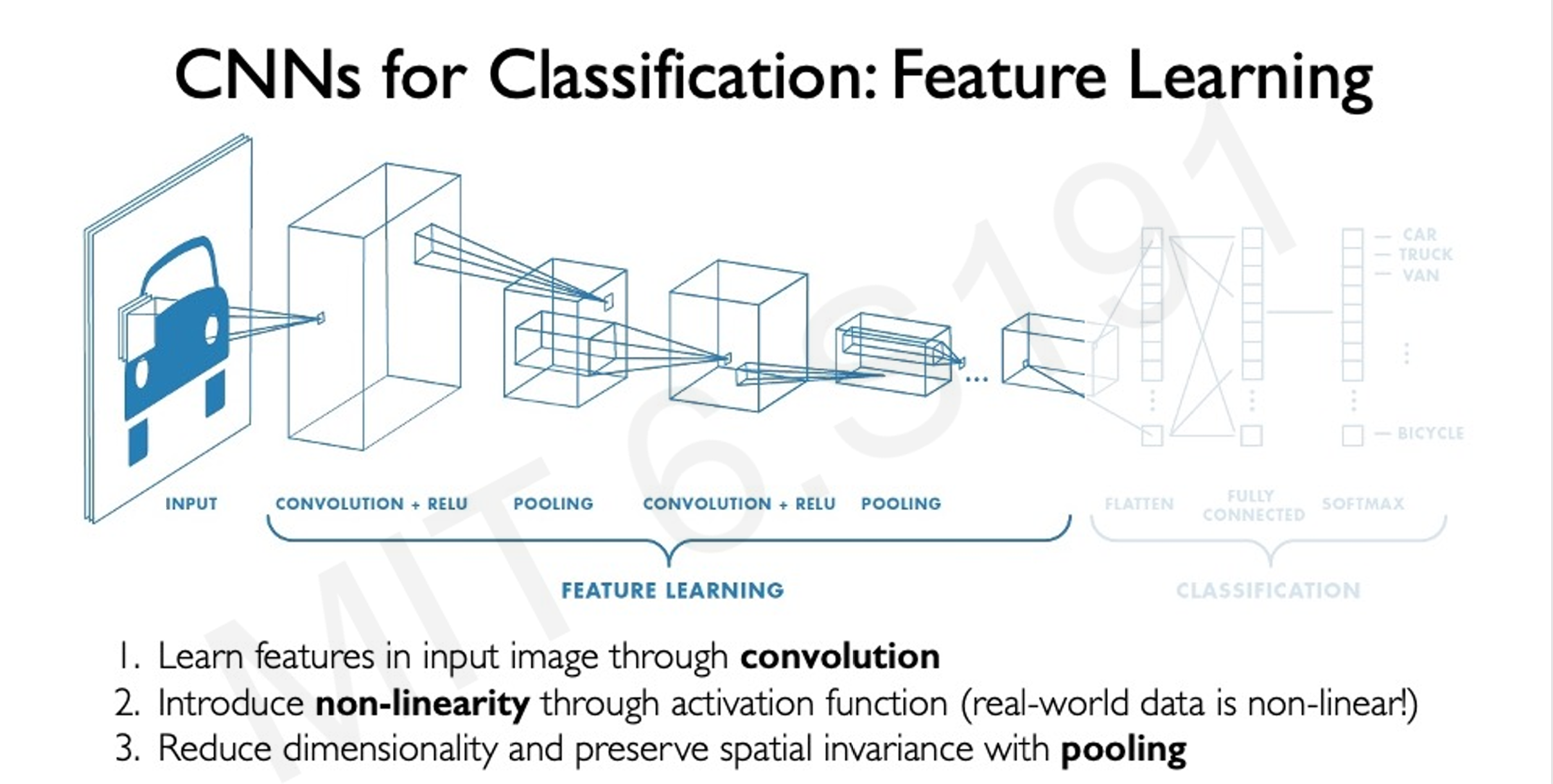
我们通过卷积操作来辨别图像中的特征。
这也是和机器学习所不一样的地方,机器学习通过人为地设计filter实现对特征的提取。
而深度学习通过大量的数据,通过神经网络的自学习,以及人类对于结果的惩罚机制来实现filter
[[卷积层]]和[[池化层]]
- 卷积层就好像是一个放大镜,将图像中的细节找出来
- 比如手写数字识别,使用16个卷积核,也就是输入为1,输出为16个通道,相当于数字维度大幅上升,我们不能对特征做简化(不然找出来干什么),但是我们可以对空间做简化,将图片变小,这也就是池化层的作用(简化信息,减少计算量,同时保留最重要的特征(比如边缘的位置)。)
- 池化层就好像是一个笔记本,将找到的细节记录下来,可以大幅减少电脑的工作量。
比如现在有28 28的图片
我们在第一轮使用卷积层找16个特征,那么维度就是16
然后使用最大池化操作,图片降低为 14 * 14
我现在的维度就是 16 * 14 * 14
第四部分:CNN的应用
4.1 分类任务
- 案例:识别图像中的物体(如汽车、卡车、自行车等)。
- 实现方式:通过CNN提取特征,然后用全连接层进行分类。
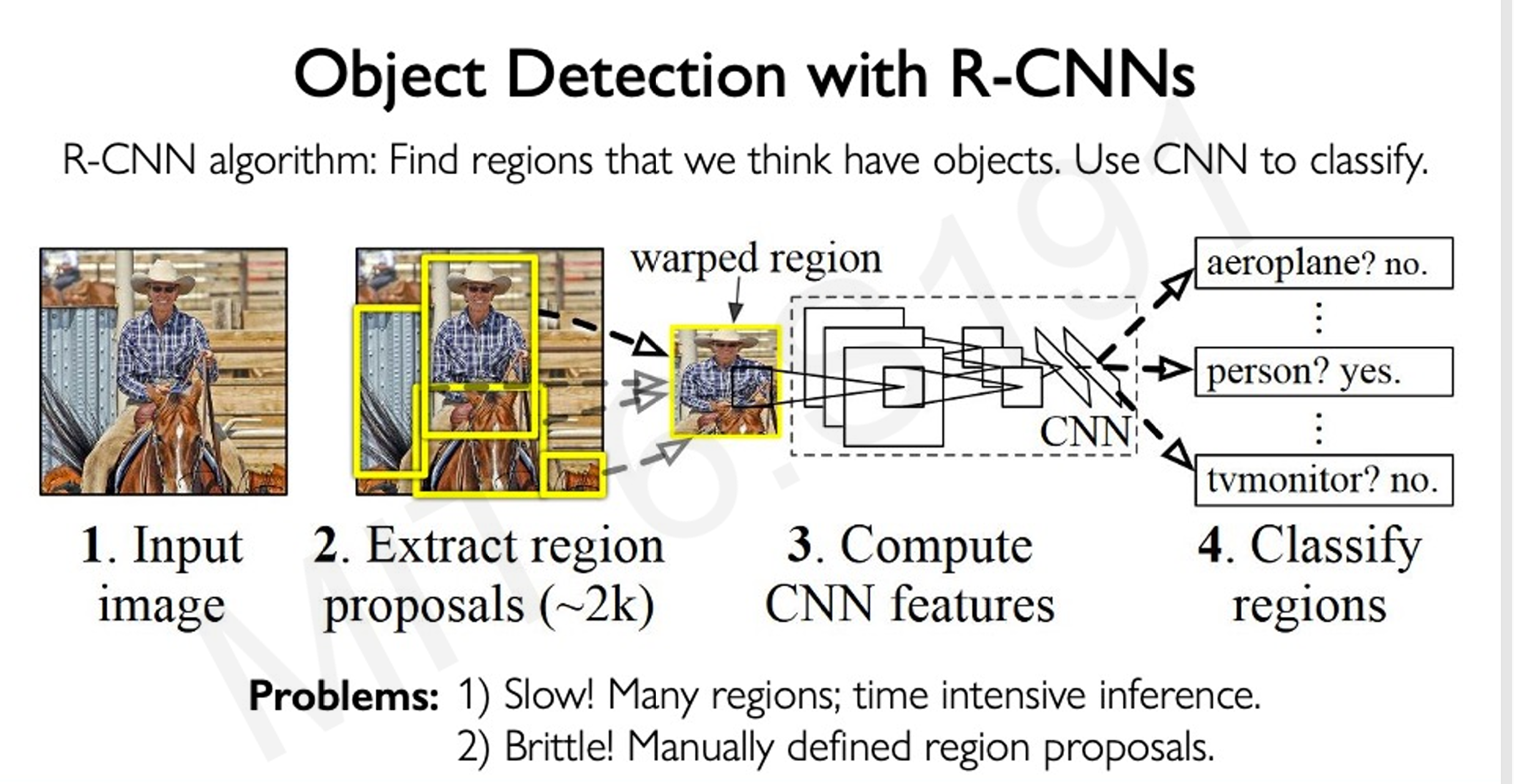
4.2 目标检测
- 目标:不仅检测物体类别,还要定位物体的边界框(bounding box)。
- 方法:使用R-CNN(区域CNN)及其改进版(如Faster R-CNN)。
- 核心思路:
- 提取图像中可能包含物体的区域(region proposals)。
- 使用CNN对每个区域进行分类和定位。
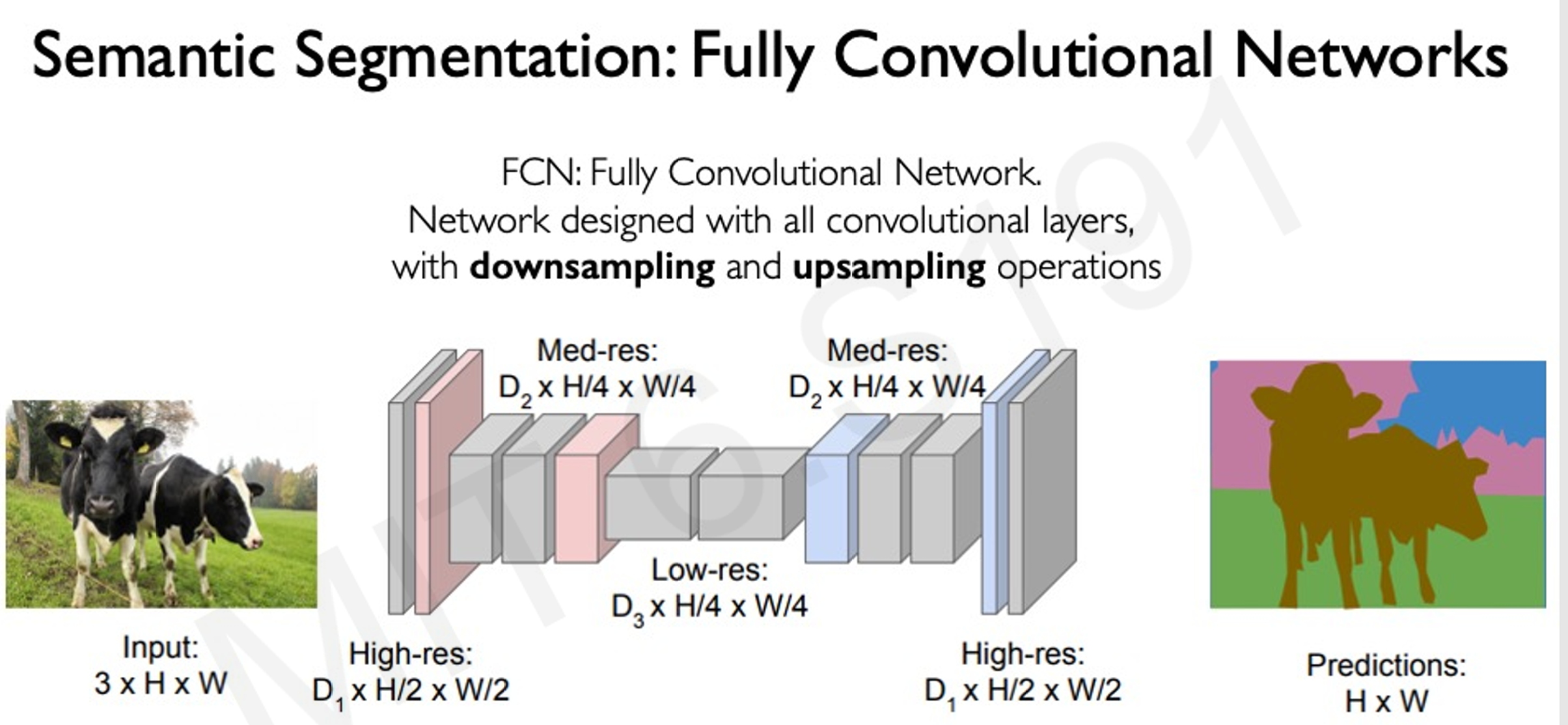
4.3 语义分割
- 目标:对图像中的每个像素进行分类。
- 实现方式:
- 使用全卷积网络(FCN)。
- 结合下采样和上采样操作,生成像素级分类结果。
4.4 自主导航
- 案例:基于视觉输入(如摄像头数据)和地图信息预测驾驶控制信号。
- 模型设计:通过CNN提取特征,结合概率控制框架实现端到端的自主驾驶。
第五部分:总结与扩展
5.1 CNN的核心优势
- 自动特征学习:从数据中自动提取特征,避免人工定义。
- 层次化特征表示:从低级到高级逐步提取特征。
- 适用于多种任务:分类、目标检测、分割和控制。
5.2 深度学习的未来与挑战
- 持续创新:深度学习在计算机视觉中的应用仍在不断扩展。
- 研究方向:如何提高模型的效率、可解释性和泛化能力。
附:代码示例
5.1 CNN模型的构建(TensorFlow)
1 | import tensorflow as tf |
5.2 CNN模型的构建(PyTorch)
1 | import torch |